Quarter of Legends: Technical Community Recap
A quarterly deep dive into the Databricks & v4c.ai technical community, covering Unity Catalog adoption, ML workflow standardization, DLT momentum, and real-world AI architecture patterns shaping teams worldwide.

This quarter marked a shift in how we share and scale knowledge across the v4c.ai & Databricks community. We took the key ideas from the Databricks Data + AI Summit 2025. We turned them into practical sessions that helped teams understand real workflows, migration paths, and design patterns for data engineering and AI.
As the momentum grew, the meetup series evolved into its new identity, Lakehouse Lagers and Legends, which reflects both the technical depth and the global community that is forming around it. And with that foundation in place, the conversations across cities surfaced a clear set of technical patterns and challenges that kept coming up. Each one shaped the focus of this quarter’s sessions.
1. Unity Catalog Adoption Is Accelerating and Becoming More Complex
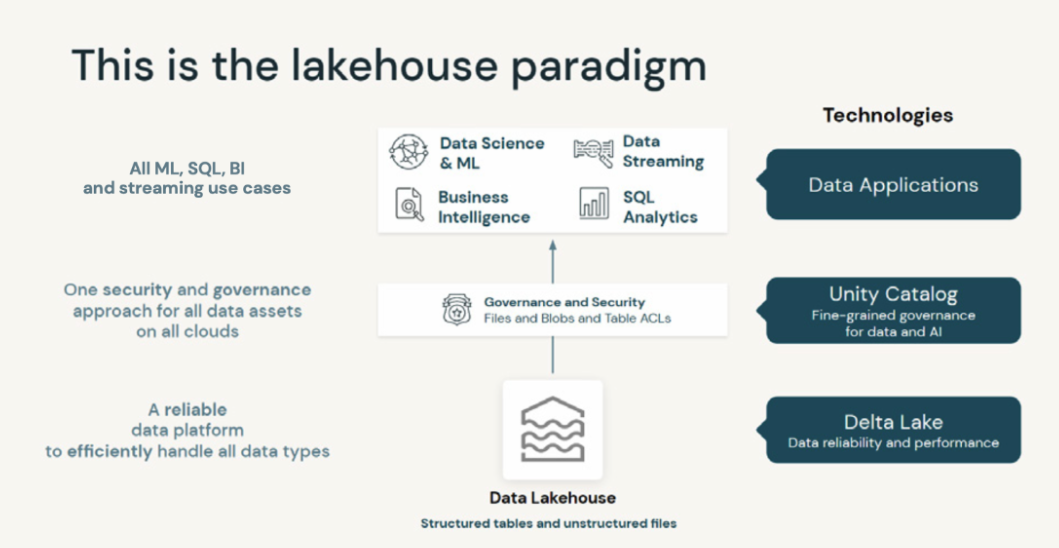
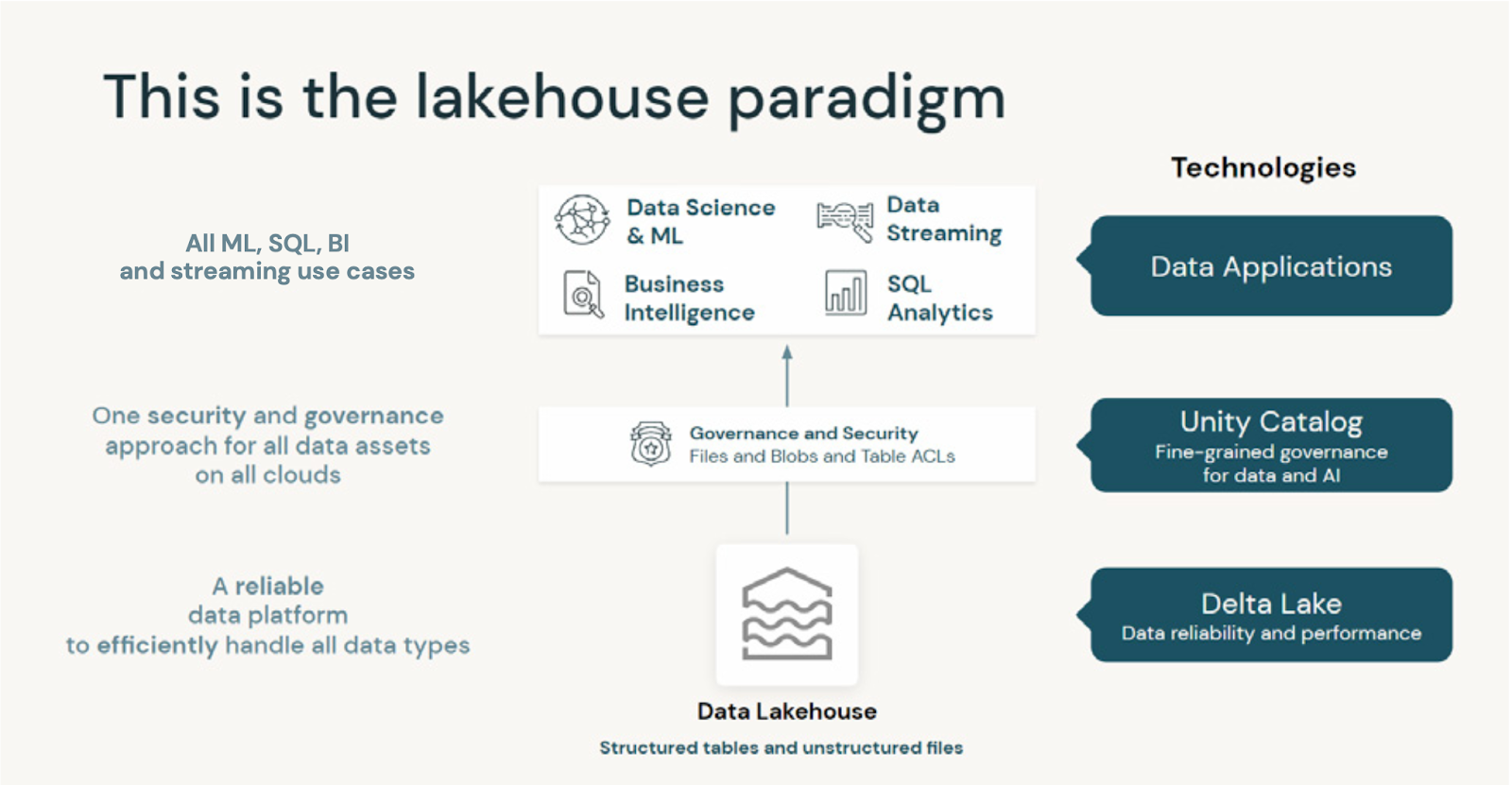
Unity Catalog (UC) came up in every city. Teams are no longer asking what it is. They are asking how to migrate safely and how to avoid breaking existing pipelines. Most teams use a mix of unmanaged tables, older permission models, and legacy scripts. They want to move to UC but need a clear path.
In these sessions, we walked through how to register unmanaged tables, how to capture lineage in a reliable way, and how to shift from individual permissions to domain-focused governance. People wanted to understand how schema evolution behaves under UC and how Machine Learning (ML) assets fit into the catalog. Once they saw how UC ties together governance, lineage, security, and AI workflow management, it became clear why Databricks treats UC as the base layer for everything going forward. The tone in the room changed from hesitation to planning.
2. Machine Learning Teams Are Asking for Standardization and Predictable Workflows
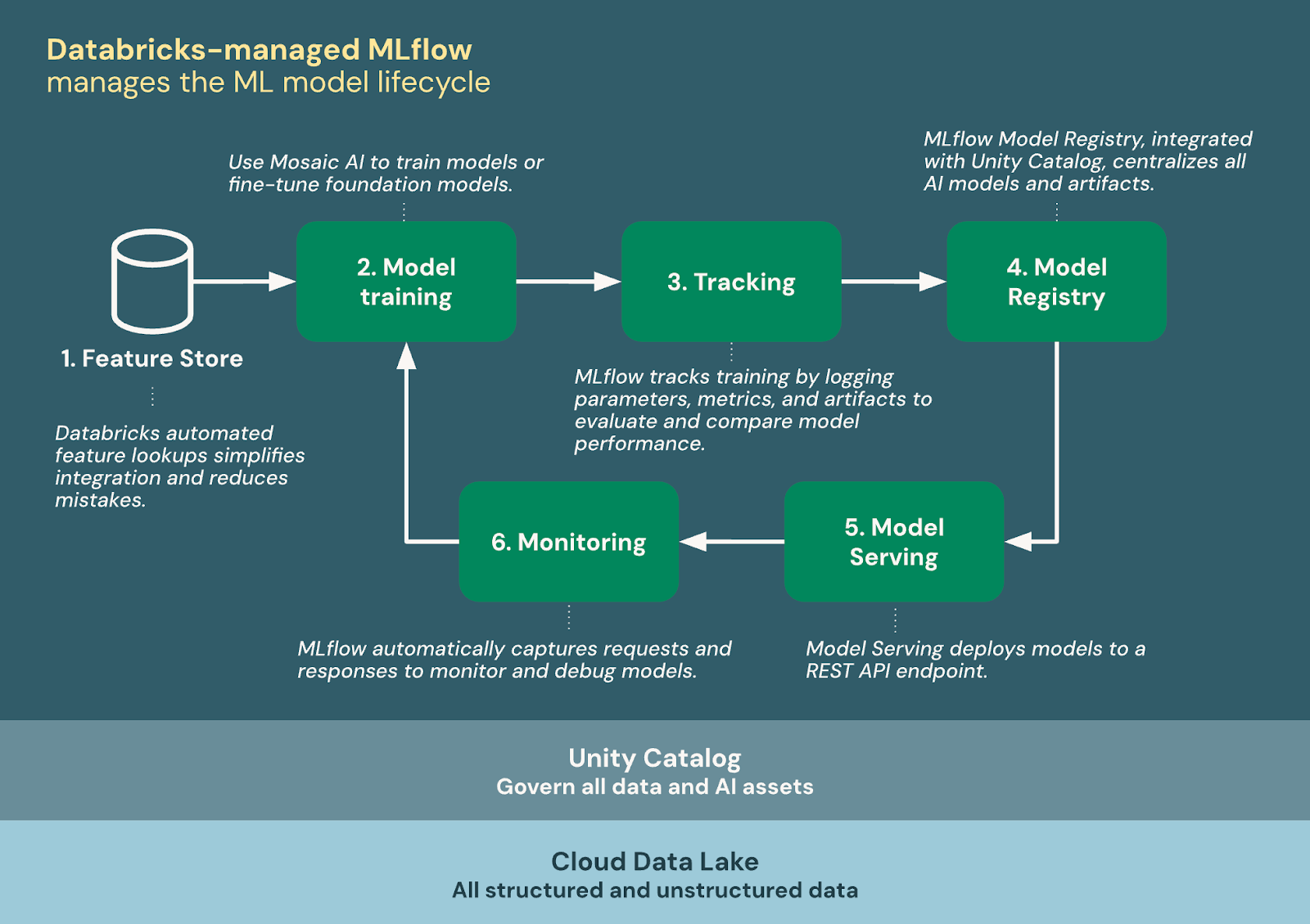
Another strong theme was the need for consistency in ML development. Many teams shared that they are dealing with scattered scripts, manual handoffs, and experiments that are difficult to reproduce. DAIS 2025 introduced new capabilities in Mosaic AI that aim to bring order to these workflows, and people wanted to understand how these updates fit together.
Across the meetups, we talked through how Feature Store can serve as a shared library of versioned features, how Model Serving provides a simpler deployment path, and how Unity Catalog brings governance into the ML lifecycle. What connected most was the idea of predictable promotion flows from development to staging to production. Teams are not looking for more tools. They are looking for shared standards that reduce the risk of drift and inconsistency. This quarter showed that ML teams are ready to work in a more structured way.
3. Delta Live Tables Became the Most Popular Topic in Every City
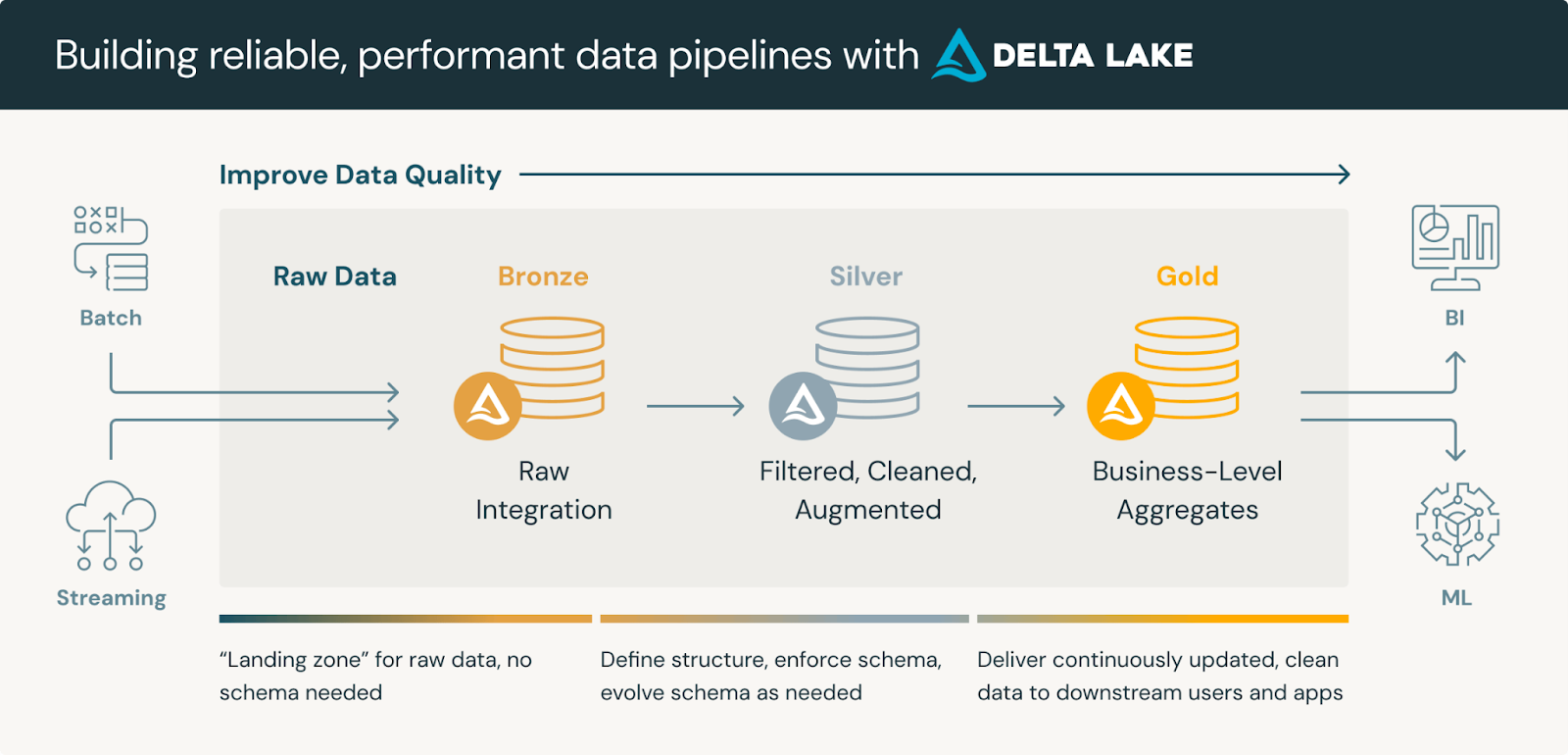
Delta Live Tables drew the strongest interest. Many teams still run pipelines through Airflow, notebooks, or cron jobs. These setups cause silent failures and require constant manual maintenance. Seeing DLT run a pipeline that is fully observable and self-managing made an immediate impression.
During the demos, we took a fragile notebook workflow and transformed it into a DLT pipeline with clear logic, built-in expectations, and structured logging. People were especially interested in how DLT handles retries, quality checks, and pipeline lineage without extra tools. Once the group saw how much operational overhead DLT removes, the conversation shifted to migration planning. DLT was the one topic that created the same excitement in every city.
4. The Databricks AI Roadmap Sparked Deep Technical Discussion
Updates from DAIS 2025 around DBRX, the Agent Framework, vector search, and Mosaic AI led to some of the most thoughtful questions of the quarter. Teams everywhere are trying to place Databricks within their AI stack and want clarity on when to use its native capabilities versus external services.
Engineers asked about inference cost, model size trade-offs, and security during fine-tuning. They also wanted to know how embeddings and vector indexes should be managed inside the lakehouse and how Databricks Agents can fit into existing orchestration patterns. Governance was a major point, especially how Unity Catalog controls access to training data, features, and models. The overall sentiment was that people want AI capabilities that feel integrated into the lakehouse. Databricks is moving in that direction, and the community is watching closely.
5. Real Use Cases Drove the Strongest Engagement Across All Cities
Participants consistently wanted real examples instead of slides. When we demonstrated how to rebuild a traditional warehouse into Delta or how to replace Airflow DAGs with DLT and Workflows, the room became more engaged. People asked about operational steps rather than conceptual points. This confirmed that hands-on walkthroughs matter more than high-level summaries.
Teams also showed rising interest in Databricks SQL for production analytics. There were questions about how to control costs while scaling SQL dashboards and how Photon improves performance. In every city, we heard the same practical problems: pipelines that are too fragile, warehouses that are slowing teams down, and ML workflows that need more structure. The community is ready for modern architecture patterns that work in production, not just in theory.
6. Dallas Confirmed That These Challenges Are Global
Our first global event under the name Lakehouse Lagers and Legends took place in Dallas and immediately showed that the same technical concerns exist outside India. The crowd raised questions about enterprise scale, governance, migration planning, and cost control across growing AI workloads.
Discussions became very open and specific. People described how they manage multiple workspaces, how they monitor spending for AI inference, and how they handle sensitive data in the lakehouse. The most valuable part of the session was the honesty. Teams shared what has worked, what has failed, and what they want the next generation of platform tools to make easier.
What Is Coming in Q4
Based on everything we heard, Q4 will focus on full hands-on builds and deeper technical content. We will run sessions on complete pipeline development, modern architecture patterns, production AI workflows, and migration playbooks.




.png)

