Storage & Governance: Building the Unified Engine for Road2Summit

.png)
Co-author: Atharva Nandurkar
The Problem Nobody Talks About
Layer 1 managed ingestion of social media tags, Q&A submissions, the journey schedule, and Lamborghini telemetry from 25 cities. However, the post-ingestion phase is often where production systems descend into chaos due to fragmented structures, scattered credentials, and conflicting sources of truth.
Road2Summit required a consistent, governed, and AI-ready foundation to power its live 9,000-mile journey, a website tracking every move, and a genie chatbot answering public questions about journey metrics.
Introducing Layer 2: Lakehouse Storage & Governance. The control tower.
The Architecture: Two Layers, One Platform
Before diving in, here's the split that made everything work:
Lakebase ad Delta Lake function as a unified platform. Workflows sync data between them, while Unity Catalog ensures consistent permissions and data visibility. Databricks Secret Scope manages all connection credentials used to connect these components.
Lakebase: The Operational Backbone
A live website needs a real operational database. Delta Lake is great for analytics, but you don't want Spark overhead on a sub-100ms API call every time a visitor clicks something. You need:
- Reliable, consistent data retrieval (leveraging PostgreSQL ACID guarantees)
- High-speed, low-latency performance is essential for real-time API interactions
- Support for UPSERT operations to maintain clean, idempotent social media data
- Efficient scale-to-zero capability to eliminate compute expenses during idle periods
Lakebase checked all these boxes and lives in the same Databricks workspace. It uses the same SDK, secret scope, and authentication model, eliminating the need for any additional infrastructure, credentials, or switching between different tools.
What We Stored
The operational layer consists of two primary tables, each designed with a specific functional goal:
- Social posts table: The social media feed. Synchronization occurred on a 30-minute cadence, with automated UPSERT logic maintaining data integrity and freshness.
- Q&A table: Public questions submitted via the site. Questions arrive hidden and unanswered. Admin approval makes them live.
The Connection Pattern
# Connection pool: reuse up to 5 connections instead of opening one per request
from psycopg2 import pool
_pool = pool.SimpleConnectionPool(
1, 5, # min 1 warm connection, max 5 concurrent
host=LAKEBASE_HOST, # resolved from Databricks secret scope at runtime
database=LAKEBASE_DB,
user=LAKEBASE_USER,
password=LAKEBASE_PASSWORD,
port=5432, # standard Postgres wire protocol port
sslmode="require", # enforce TLS — mandatory for production
connect_timeout=10, # fail fast if Lakebase hasn't warmed up yet
)
No exotic drivers or custom SDKs required. Because it uses the standard PostgreSQL wire protocol, any Python or Node.js developer can connect to Lakebase the same way they would to any standard PostgreSQL database.
Key insight: Scale-to-zero functionality was the deciding factor for production. Lakebase drops to zero compute during quiet hours and warms up within seconds on the first request. For a campaign with bursty traffic, this eliminated idle compute cost entirely.
Delta Lake: The Analytical Foundation
Lakebase handles live app data. Delta Lake handles everything that needs to be queried, analyzed, or fed to AI. We maintain two analytical Delta tables in our gold schema:
The Journey Schedule Table
The 35-day journey schedule. Sourced from an Excel file, transformed by a PySpark job, and written to Delta once. This table is the source of truth for every schedule-related question Genie answers.
#Read schedule Excel from UC Volume inherits UC governance and lineage automatically
df = spark.read.format("com.crealytics.spark.excel") \
.option("header", "true") \
.load("/Volumes/your_catalog/raw/schedule/journey_schedule.xlsx")
df_clean = (
df
#Forward-fill week source Excel merges week cells vertically
.withColumn("week", F.last("week", ignorenulls=True).over(w))
# Parse date string into DateType for reliable filtering
.withColumn("stop_date", F.to_date("stop_date", "MM/dd/yyyy"))
# Derive clean event_type categorical from raw is_overnight flag
.withColumn("event_type", F.when(F.col("is_overnight") == "Y", "overnight")
.otherwise("pit_stop"))
)
# Overwrite makes this job idempotent safe to re-run if the schedule changes
df_clean.write.format("delta").mode("overwrite") \
.saveAsTable("your_catalog.gold.journey_schedule")
Key insight: mode='overwrite' makes the ingest idempotent. If the schedule changes, re-running the job gives you a clean, correct table: no manual deletes, no incremental complexity.
The Social Posts Mirror
This serves as the Delta Lake mirror of the production social posts table within Lakebase. It exists because Genie can only query Delta tables in Unity Catalog. We run a scheduled Workflow that syncs Lakebase → Delta tables on a regular cadence.
# Genie can only query Delta tables — this job syncs Lakebase → Delta on a schedule
conn = psycopg2.connect(host=LAKEBASE_HOST, database=LAKEBASE_DB,
user=LAKEBASE_USER, password=LAKEBASE_PASSWORD)
# Fetch only approved posts — keeps hidden content out of Genie's query scope
df_pd = pd.read_sql("SELECT * FROM social_posts WHERE is_visible = true", conn)
# Convert to Spark DataFrame before writing to Delta
df_spark = spark.createDataFrame(df_pd)
# Full overwrite — always a clean snapshot, no stale rows, no merge complexity
df_spark.write.format("delta").mode("overwrite") \
.saveAsTable("your_catalog.gold.social_posts")
When a visitor asks Genie, "What are the top posts this week?', it converts the question into a SQL query and runs it against a fresh, governed, and indexed Delta table, not a live Postgres database or an old CSV export—a proper analytical table with full Unity Catalog lineage.
Unity Catalog: Governance That Doesn't Get in the Way
The Permission Model
Everything in our workspace runs under a service principal, an application identity that our backend applications authenticate as. Before we could query anything, we had to grant permissions explicitly:
-- UC requires explicit access at every level: catalog → schema → table
-- No wildcards. Each table granted individually — essential for a public-facing Genie.
GRANT USE_CATALOG ON CATALOG your_catalog TO `your-service-principal`;
GRANT USE_SCHEMA ON SCHEMA your_catalog.gold TO `your-service-principal`;
GRANT SELECT ON TABLE your_catalog.gold.journey_schedule TO `your-service-principal`;
GRANT SELECT ON TABLE your_catalog.gold.social_posts TO `your-service-principal`;
No wildcard grants or GRANT ALL PRIVILEGES. Permissions are assigned only to specific tables and actions. By adhering to the least-privilege principle, this approach effectively mitigates the risk of accidental data leakage.
Key insight: When you embed Genie in a public-facing website, you're exposing NL→SQL to the open internet. The service principal used for Genie queries has access only to the tables it needs, not to anything else. Unity Catalog's ACL model makes least-privilege the default, not an afterthought.
Data Lineage
Unity Catalog tracks lineage automatically. Our gold tables show a clear chain:
- UC Volume (schedule.xlsx) → Serverless PySpark job → your_catalog.gold.journey_schedule
- Lakebase (social posts table) → Scheduled Workflow → your_catalog.gold.social_posts
When someone asks, 'Where does this data come from?', the answer is in the UI and not in documentation that's three sprints out of date.
Unity Catalog Volumes
Volumes are Unity Catalog-governed file storage, a managed location that plays by the same rules as your tables. We stored the journey schedule Excel file at /Volumes/your_catalog/raw/schedule/journey_schedule.xlsx that was:
- Discoverable: shows up in Unity Catalog Explorer alongside the tables
- Governed: same ACL model as Delta tables
- Portable: the PySpark ingest job references the same path regardless of which cluster runs it
Secret Scope: Credentials Done Right
The Databricks secret scope serves as the central hub for all connections within Road2Summit.
# WorkspaceClient auto-authenticates using the job's ambient identity — no token needed
from databricks.sdk import WorkspaceClient
wc = WorkspaceClient()
# Pull credentials from secret scope at runtime — nothing hardcoded, nothing in version control
# Rotating a credential means updating it once here; all services pick it up automatically
LAKEBASE_HOST = wc.secrets.get_secret("your-scope", "lakebase_host").value
LAKEBASE_DB = wc.secrets.get_secret("your-scope", "lakebase_db").value
LAKEBASE_USER = wc.secrets.get_secret("your-scope", "lakebase_user").value
LAKEBASE_PASSWORD = wc.secrets.get_secret("your-scope", "lakebase_password").value
Just a few lines of code. No .env files stored in version control, hardcoded connection strings in notebooks, or IAM policies to write. To maintain a robust security posture, the service principal is granted READ-only permissions within this designated scope.
Key insight: The secret scope is the single place where credentials live. When credentials rotate, you change them in one place. Every service, the FastAPI backend, Serverless ingest jobs, and Workflows pick up the change on the next startup—no deployment required.
How the Two Layers Connect
Here's the full picture of how operational data flows into analytical data:
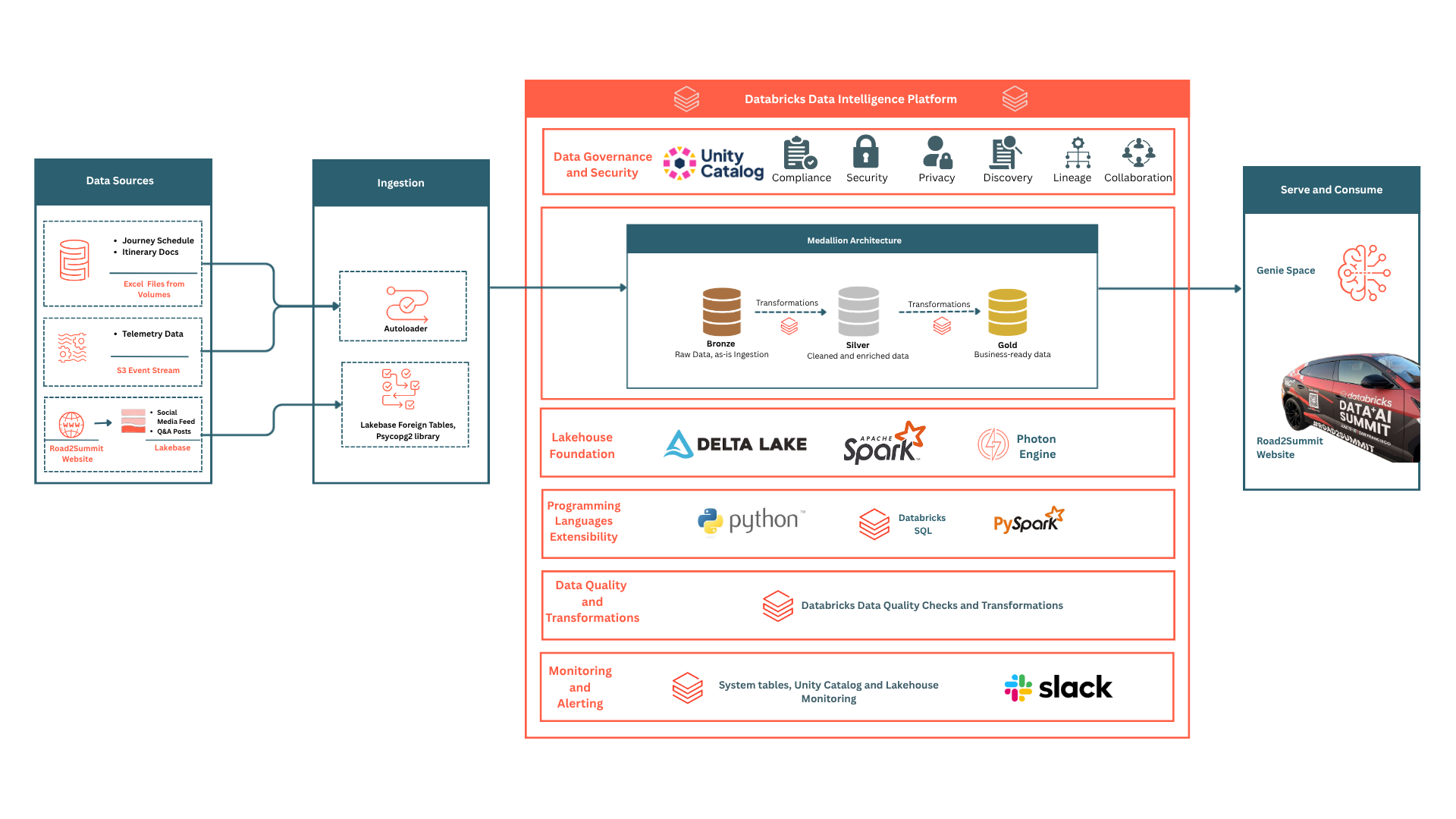
- Website visitors interact with a FastAPI backend (via psycopg2), which communicates with Lakebase for social posts and Q&A.
- A scheduled Databricks Workflow synchronizes this data into Delta Lake gold tables.
- All gold tables are governed by Unity Catalog, providing robust ACLs and lineage.
- Genie uses NL→SQL via a SQL Warehouse to provide answers to site visitors.
The API powers the website, while the mirror supports the AI. Everything is managed by Unity Catalog and secured via Secret Scope, ensuring a leak-proof architecture.
How You Can Build On This
If you're building a similar multi-source data platform, whether it's a marketing campaign tracker, a logistics dashboard, or an event management system, here's the pattern that worked for us:
The Dual-Layer Rule
Avoid using a single system for both real-time operations and large-scale analytics. Lakebase (operational) and Delta (analytical) are different tools for different problems. Connect them with a scheduled sync, and you get the reliability of PostgreSQL for your live app and the query power of Delta for your AI layer.
Permissions First, Always
Before you write a single table, set up your Unity Catalog permissions model:
- GRANT USE_CATALOG on your catalog to your Service Principal
- GRANT USE_SCHEMA on each schema your Service Principal needs
- Add SELECT grants per table as you create them, never GRANT ALL
One Secret Scope
Begin by consolidating all your credentials within a single Databricks secret scope. Use clear, descriptive key names (such as lakebase_host instead of just host) and restrict access by granting READ permissions only to service principals that require them.
Volumes for Source Files
If you have source files (Excel imports, reference CSVs, RAG PDFs), put them in Unity Catalog Volumes, not raw S3 paths. You get lineage, discoverability, and consistent access control for free.
Mirror for AI Readiness
If you want Genie (or any NL-to-SQL system) to query your operational data, create a Delta mirror in your gold schema. The sync adds a small lag, minutes, not hours, but your AI layer always operates on properly governed, indexed, analytical tables rather than a live production database.
Key Principles to Follow
- Treat governance as infrastructure, not overhead. Setting up UC permissions may feel like extra work upfront, but it's what enables teams to move fast without breaking things downstream.
- Use scale-to-zero as a deliberate cost strategy. Lakebase's scale-to-zero eliminates idle compute costs during off-hours, with no scheduled jobs or manual intervention required.
- Separate operational and analytical reads. Keep your website fast by reading from Postgres, and keep your AI accurate by pointing it at governed Delta tables; don't force one layer to serve both purposes.
What's Next?
We've covered ingestion and storage. Data is flowing in, governed, consistent, and AI-ready. But governed data sitting still isn't enough. It needs to move, be transformed, be orchestrated, and be kept fresh on a schedule without any idle compute cost.
Up next, we will explore Layer 3: Compute & Orchestration - how Databricks Workflows and Serverless Compute kept three pipelines running across 35 days without a single cluster to manage. Stay tuned.
Key Takeaways
- The Lakebase and Delta combination serves as a mandatory dual-layer architecture. While Lakebase manages operational write activities, analytical querying is directed to Delta.
- Using Unity Catalog ACLs ensures that AI agents have precise access permissions. This level of governance is critical for securely integrating NL-to-SQL functionality into public platforms.
- Secret Scope is the single source of truth for credentials; one change point without any .env files or hardcoded strings.
- Unity Catalog Volumes provide source files with the same level of governance, lineage, and discoverability as standard tables, at no additional cost.
- Delta mirrors enable AI-ready operational data without impacting your live production environment.
Ask Genie anything about the Road2Summit journey at road2summit.ai, it's running on exactly the stack described here.
Recommended Reads




.png)

