Databricks-Powered High-Speed Ingestion: Paving the Road2Summit

.png)
Co-author: Jyotirka Rout
Category: Data Engineering | Databricks Lakehouse
Where It All Begins
Every data story starts with a single question: How do we bring data in?
For Road2Summit, a 9,000-mile cross-country journey from NYC to San Francisco, that question had a unique twist. We needed to ingest data from disparate sources, at highly variable velocities, all feeding into a single, unified platform that powers real-time AI conversations and live telemetry dashboards.
This is the story of Layer 1: Data Ingestion, where raw signals are transformed into actionable insights.
The Challenge: Multiple Sources, One Pipeline
When we kicked off Road2Summit, we faced a classic data architecture puzzle: How do you unify diverse ingestion patterns without creating chaos?
Our data sources looked like this:
- Journey Schedule: An Excel file with 35 days of planned stops, locations, and events (batch)
- Social Media Feed: Real-time feed from social media monitoring(streaming, continuous, every 30 minutes)
- Public Q&A: Questions submitted by website visitors (event-driven, asynchronous)
- Live Vehicle Telemetry: High-fidelity, real-time data (GPS coordinates, speed, engine hours) streamed from the Lamborghini Urus at 15-second intervals.
Three different patterns. Three different expectations. One platform.
The traditional approach would have been to build three separate pipelines, fight with schema conflicts, and debug inconsistencies for months. Instead, we chose Databricks Lakebase as our operational layer, a managed PostgreSQL database that could handle all three patterns simultaneously, with built-in UPSERT semantics and real-time availability.
How We Built It
1. High-Level Architecture Diagram
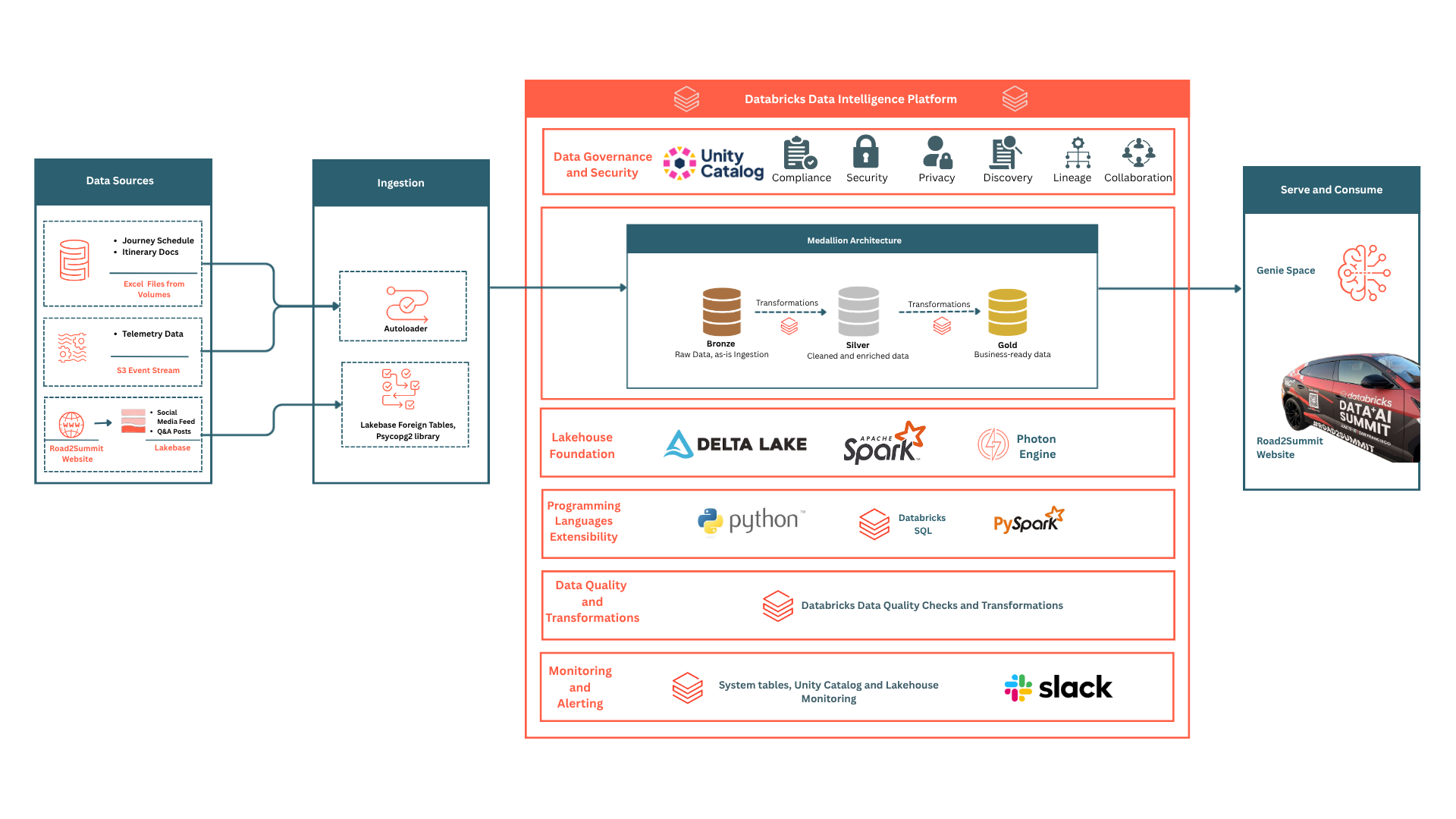
2. Journey Schedule - Precision Batch Processing
The journey schedule served as our absolute source of truth, capturing every milestone and pit stop. While it began as a modest 35-row Excel file, transforming it into a high-octane data asset required a meticulous preparation process:
- Forward-fill missing weeks
- Classify event types (pit stop, major city, overnight, arrival)
- Fix column data types
- Normalize location names
To power this transformation, we leveraged:
- A Databricks Serverless job running a PySpark notebook
- The raw Excel file is read directly from a Unity Catalog Volume via Spark.
- PySpark DataFrame transformations to clean and validate
- Delta Lake is our reliable destination for the final aggregated dataset
This streamlined job was executed once at the start of our trek without any complex polling or fragile incremental logic required. It was a simple, reliable, and perfectly repeatable ingest.
Key insight: Even batch processes benefit from being idempotent.
3. Social Media Feed: Streaming Ingestion at Scale
Real-time monitoring of social media feeds required a fundamentally different approach. To achieve this, we built a Node.js monitoring service that runs every 30 minutes and pulls fresh data.
The architecture:
Hashtag Feed → Extract engagement → UPSERT into Lakebase PostgreSQL
The magic word here is UPSERT ON CONFLICT. We treat each social media feed as having a unique ID. If it's new, we INSERT. If it already exists, we UPDATE.
- Zero duplicates
- Always-fresh engagement metrics
- No manual deduplication logic
- Delta tables auto-mirrored, powering Genie for instant Q&A
Key insight: UPSERT patterns are essential for streaming data where you need idempotency and freshness.
4. Open Comms Q&A: Event-Driven with Admin Approval
When website visitors engage with our Open Comms Q&A, their questions initiate an event-driven flow. Initially, these questions land in Lakebase as hidden and unanswered, awaiting administrative review in our dedicated Streamlit dashboard before being marked as visible and answered.
The flow:
- User submits question → FastAPI POST /api/open-comms
- INSERT into Lakebase Q&A table (hidden=false, answered=false)
- Admin reviews in Streamlit
- UPDATE: response_text, answered=true, visible=true
- GET /api/open-comms (next 30s poll)
- Live on the Dialogue Engine section
The Autoloader Approach: Scaling to S3
While Road2Summit's ingestion sources were relatively small, many real-world systems receive terabytes of data daily in cloud storage. This is where Databricks Autoloader becomes essential.
Autoloader functions as the ingestion engine that provides:
- An Apache Spark connector that automatically detects new files in S3/cloud storage
- A managed solution designed to handle late-arriving data, duplicates, and schema evolution
- Infinitely scalable without relying on costly polling overhead
How you'd use it for a Road2Summit-like system with high-volume telematics:
df = spark.readStream \
.format("cloudFiles") \
.option("cloudFiles.format", "parquet") \
.load("s3://my-bucket/motive/telemetry/")
df.writeStream \
.format("delta") \
.outputMode("append") \
.table("telemetry_events_delta")
Key Benefits:
- Exactly-once semantics with checkpointing
- Automatic schema inference and evolution
- No batch interval limitations
- Can scale to billions of events per day
How You Can Build On This
For Batch Data (Schedules, Reference Data)
- Store source files in Unity Catalog Volumes (or cloud storage) for centralised access.
- Use Databricks Serverless Compute with PySpark for efficient transformation.
- Write the final data to Delta Lake with mode='overwrite' for idempotency, allowing you to re-run the job safely.
- Don’t forget to version control your notebooks in a Git repository for collaboration and auditability
For Streaming Data (Social Feeds, APIs)
- Build a lightweight polling service (using Node.js, Python, or Go)
- UPSERT into Lakebase using ON CONFLICT semantics
- Create a Delta mirror table via a scheduled Workflow for analytics
- Set up Genie Spaces to answer business questions on that Delta data
For Event-Driven Data (Form Submissions, Webhooks)
- Accept event data via FastAPI (or your preferred REST framework)
- Write events directly to Lakebase PostgreSQL for consistency
- Allow GET endpoints to read directly from Lakebase with caching
- Use Streamlit dashboards to streamline administrative approval workflows
For High-Volume Cloud Data
- Archive required data to S3 in columnar format (Parquet)
- Ingest raw data using Autoloader within a Structured Streaming job
- Write structured data to Delta with exactly-once guarantees
- Expose delta tables via a SQL Warehouse for analytics
The Reliability Imperative
When you're live-streaming data about a multi-week journey, reliability isn't optional- It’s everything. Here are the patterns that kept Road2Summit ingestion rock-solid:
1. Idempotency
Every ingest job could be re-run without fear. UPSERT patterns meant duplicates were never a problem.
2. Dead Letter Handling
If a record didn't parse correctly, we logged it and moved on. This ensured the admin could review unparseable records in a separate queue.
3. Observability
Every ingest was written to Databricks Jobs logs, which we monitored. Any failures automatically triggered immediate Slack alerts.
4. Lakebase Autoscaling
Our operational tables never had to worry about compute resources. Lakebase scaled from zero to peak automatically, then scaled back down after 5 minutes of idle time.
Key Takeaways
- Multiple ingestion patterns can coexist using Lakebase's UPSERT semantics and Delta Lake's reliability.
- Batch, streaming, and event-driven data require different approaches, but they all feed the same Lakehouse.
- Autoloader is the bridge to cloud-scale ingestion without the polling overhead.
- Serverless compute lets you ingest without managing infrastructure
- Reliability comes from idempotency; design your pipelines to be re-runnable
What's Next?
Ingestion is where the data journey begins, but it's just the start.
Once data lands in Lakebase and Delta, it needs to be unified, governed, and queryable. That's Layer 2: Lakehouse Storage & Governance on road2summit.ai
Stay tuned for the next article to explore the ins and outs of Layer 2: Lakehouse Storage & Governance coming soon.
Recommended Reads
- What is a Lakebase
- How Lakebase Architecture Delivers 5x Faster Postgres Writes
- A New Era of Databases: Lakebase


.png)

.png)
