The GPS for Data: Why Manual Pipelines are Over
Simplify Batch and Streaming ETL with Automated Reliability and Governed Data Quality using Lakeflow Spark Declarative Pipelines.

.png)
Overview
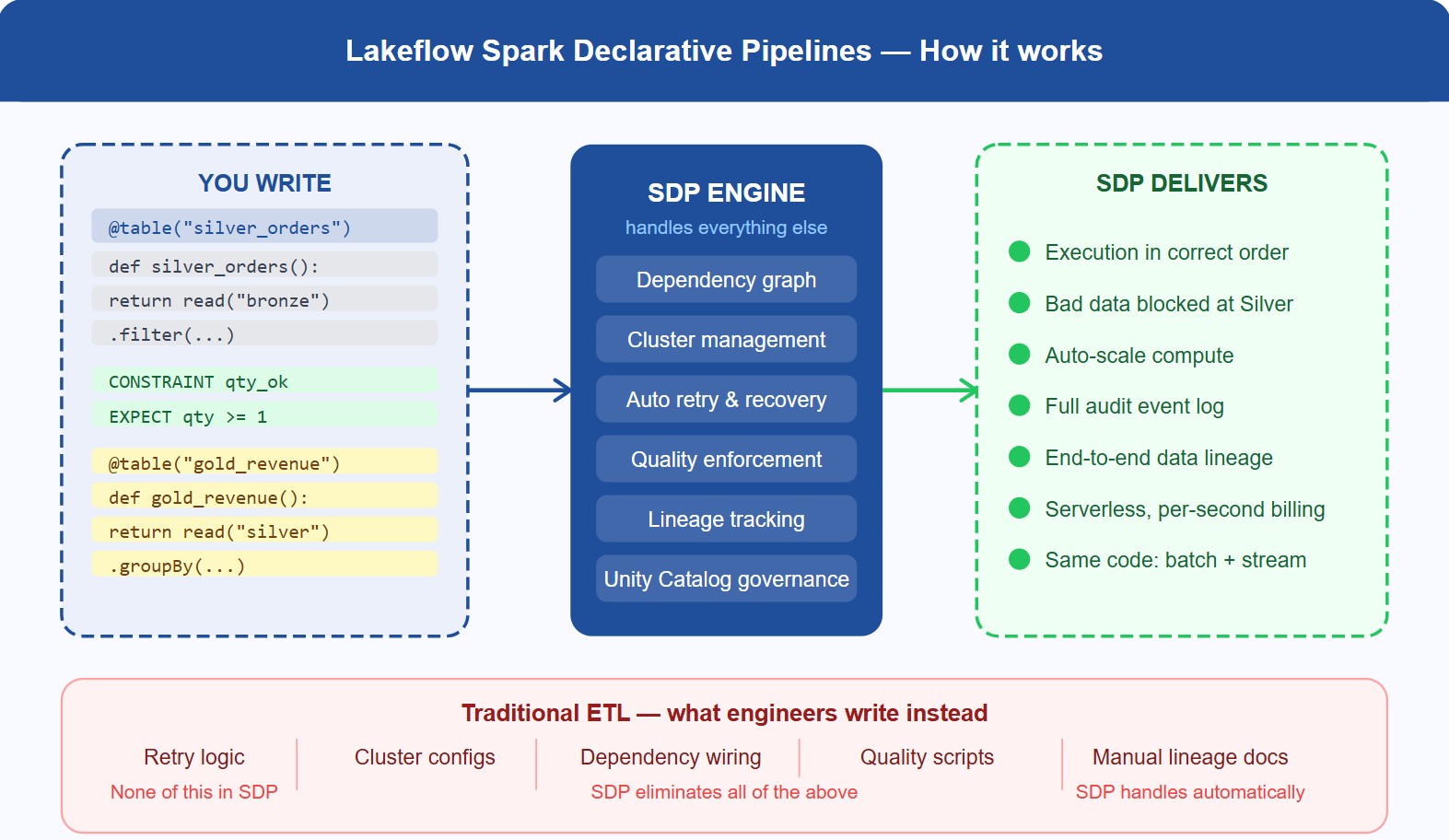
Building data pipelines the hard way, writing retry logic, managing clusters, and maintaining quality scripts are patterns most engineering teams know too well. Lakeflow Spark Declarative Pipelines (SDP) is Databricks' answer: a declarative ETL framework built into the Lakehouse Platform that handles operational overhead. Hence, your team focuses on what the data should actually look like.
The Problem with Traditional ETL
A pipeline breaks overnight. Dashboards show incorrect numbers. Root cause: an undocumented schema change. The job gets patched, and then it just happens again. Most data engineering teams spend their week reacting, maintaining systems, and rarely moving forward.
Traditional ETL tools were designed for a quieter era. Schemas now change without warning, business teams need real-time answers, and data streams in from dozens of sources simultaneously. Engineers are expected to build new pipelines while keeping old ones from falling apart.

What Is Lakeflow SDP?
Lakeflow Spark Declarative Pipelines, the evolution of Delta Live Tables (DLT), is a declarative ETL framework built natively into Databricks. Under the Lakeflow brand, Databricks unified ingestion (Lakeflow Connect), transformation (SDP), and orchestration into one seamless platform. In a traditional ETL job, engineers write imperative, step-by-step code. With SDP, you declare the outcome: define tables, quality rules, and transformations, and SDP resolves dependencies, manages the cluster, handles retries, and tracks lineage automatically. SDP works in both Python and SQL. SQL analysts write production pipelines without touching Spark internals. Python engineers are familiar with a syntax that hides declarative power underneath.
Think of it this way: writing traditional ETL is giving someone turn-by-turn directions. SDP is dropping a pin. You decide the destination, and SDP handles every turn.
How SDP Works: Medallion Architecture in Code
The following pipeline covers all three Medallion layers: Bronze ingestion, Silver validation, Gold aggregation in a single declarative codebase:
from pyspark import pipelines as dp
from pyspark.sql.functions import col, from_json, to_date
# Define schema for Kafka JSON payload
ORDER_SCHEMA = "order_id STRING, customer_id STRING, store_id STRING,
region_id STRING, order_date STRING,
quantity INT, unit_price DOUBLE, profit DOUBLE"
# BRONZE - ingest raw Kafka events, preserve all fields
@dp.table(name=‘bronze_orders’, comment=‘Raw Kafka events - source of truth’)
def bronze_orders():
return (spark.readStream.format('kafka')
.option('kafka.bootstrap.servers', dbutils.secrets.get('scope','broker'))
.option('subscribe', 'orders_topic')
.load()
.select(from_json(col('value').cast('string'), ORDER_SCHEMA).alias('d'))
.select('d.*'))
# SILVER - validate and clean; @dp.table outermost, @dp.expect_or_drop closest to def
@dp.table(name=‘silver_orders’, comment=‘Validated, typed order records’)
@dp.expect_or_drop(‘qty_ok’, ‘quantity >= 1’)
@dp.expect_or_drop(‘price_ok’, ‘unit_price > 0’)
@dp.expect_or_drop(‘has_customer’, ‘customer_id IS NOT NULL’)
def silver_orders():
return (dp.read_stream(‘bronze_orders’) # SDP resolves dependency auto
.select(col('order_id'), col('customer_id'), col('store_id'), col('region_id'),
to_date(col('order_date'),'yyyy-MM-dd').alias('order_date'),
(col('quantity') * col('unit_price')).alias('revenue'),
col('quantity').cast('int'), col('unit_price').cast('double'), col('profit').cast('double')))
# GOLD - aggregate for dashboards; SDP handles Silver dependency
@dp.table(name=‘gold_daily_revenue’, comment=‘Daily revenue by store’)
def gold_daily_revenue():
return (dp.read(‘silver_orders’) # SDP knows Silver runs first
.groupBy('order_date','store_id','region_id')
.agg({'revenue':'sum','profit':'sum','quantity':'sum'}))
Notice what is absent: No retry handler, no cluster config, no dependency wiring, no lineage setup. SDP reads the table definitions, automatically builds the execution graph, and ensures bad data cannot propagate downstream.
SQL teams get identical behaviour with native syntax:
-- SQL equivalent of the Silver layer
CREATE OR REFRESH STREAMING TABLE silver_orders
CONSTRAINT qty_ok EXPECT (quantity >= 1) ON VIOLATION DROP ROW
CONSTRAINT price_ok EXPECT (unit_price > 0) ON VIOLATION DROP ROW
CONSTRAINT has_customer EXPECT (customer_id IS NOT NULL) ON VIOLATION DROP ROW
AS SELECT * FROM STREAM(bronze_orders); -- SDP resolves dependency automatically
Same constraints, same dependency resolution, same output. Your SQL analysts write pipelines the same way your Python engineers do.
Two Execution Modes, One Pipeline
Switching between modes requires a single configuration change. Pipeline logic, quality rules, and the dependency graph remain identical.
Serverless SDP - Databricks Benchmarks: Up to 5× better price-to-performance for ingestion vs classic compute. Up to 98% cost savings on complex transformations. Per-second billing. Real result: Jet Linx Aviation cut raw-to-Silver processing from 16 min to 7 min after switching to serverless SDP. (Source: Databricks Blog, August 2024)
SDP vs Traditional ETL
Source: Databricks Product Docs · Hevo ETL Trends Report 2026 · Invgate SDP Review
Medallion Architecture Layer Guide
<table border="1" cellpadding="10" cellspacing="0" style="border-collapse: collapse; width: 100%; font-family: Arial, sans-serif;">
<thead>
<tr style="background-color: #f2f2f2;">
<th style="text-align: left; width: 20%;">Layer</th>
<th style="text-align: left;">Description</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>🥉 Bronze</strong></td>
<td>Raw ingestion as received - CSV via Auto Loader, Kafka via Structured Streaming, CDC from databases. No filtering. <code>cloudFiles.schemaEvolutionMode='addNewColumns'</code> handles schema drift automatically.</td>
</tr>
<tr>
<td><strong>🥈 Silver</strong></td>
<td>Where data becomes trustworthy, duplicates are removed, formats are standardized, and SDP expectations are applied to every record by default. Records failing rules are dropped or quarantined before reaching downstream consumers. SCD Type 2 manages dimension history natively via <code>APPLY CHANGES INTO</code>.</td>
</tr>
<tr>
<td><strong>🥇 Gold</strong></td>
<td>Silver shaped for consumption - star schemas, daily aggregates, KPI tables. Unity Catalog enforces row-level security by role: regional managers see their region, analysts get read-only scoped access. No manual access management required.</td>
</tr>
</tbody>
</table>Prerequisites & Limitations
Prerequisites
- Databricks workspace (AWS / Azure / GCP) at Premium tier or higher
- Unity Catalog: required for lineage, access control, and audit logging
- Python or SQL familiarity: basic understanding of Spark functions
- Data sources accessible through a Databricks-supported connector
Known Limitations
- No circular dependencies allowed- The pipeline graph must be strictly directional
- Column renaming may require a full pipeline rerun (adding columns is automatic)
- Fixed topology- Pipeline structure cannot change mid-run based on data content.
- Premium tier only- Verify this before designing the architecture.
When SDP Is the Right Choice
SDP delivers the most value when these conditions are met. Use the table below to decide:
To deploy, navigate to Lakeflow → Pipelines in the Databricks UI, or use the CLI: databricks pipelines deploy pipeline.yml. Terraform is also supported for infrastructure-as-code teams.
Key Takeaways
- SDP is the evolution of Delta Live Tables, now part of the unified Lakeflow platform, which covers ingestion, transformation, and orchestration.
- Declarative pipelines eliminate the need for manually written orchestration logic, retry handlers, cluster configuration, and dependency wiring.
- One SDP pipeline handles both batch and streaming, with no dual codebases or separate failure modes.
- Built-in @dp.expect_or_drop quality enforcement runs on every pipeline execution, not as an afterthought.
- Native Unity Catalog delivers end-to-end lineage, row-level access control, and full audit logging out of the box.
- Serverless SDP delivers up to 98% cost savings on complex transformations with per-second billing and zero cluster management.
How v4c.ai Can Help
v4c.ai is a pure-play Databricks services partner with 600+ certifications, 400+ practitioners, and 150+ enterprise clients across Financial Services, Retail, Manufacturing, and Healthcare. Every engineer reviewing your architecture has built real SDP pipelines in production.
Beyond initial setup, we provide deep-dive architectural audits to identify bottlenecks in your current ETL workflows and migrate them to Lakeflow seamlessly. We specialize in implementing advanced Unity Catalog governance models to ensure your automated pipelines remain compliant and secure. Whether you are looking to optimize for cost or performance, v4c.ai offers hands-on engineering support to turn your data strategy into a scalable, serverless reality.
Sources
1. Databricks - Spark Declarative Pipelines official documentation
2. Databricks Blog - Serverless compute for SDP benchmarks, August 2024
3. v4c.ai - 500 Databricks Certifications press release, March 31, 2026
4. v4c.ai - Client Impact Stories
More blog posts

.png)
